最近牙疼,吃什么都不香,为了省点拔牙钱,排队办市民卡,郁闷,于是写文章解闷。
嗯……那就从一个简单的爬虫开始吧。
运行环境:Ubuntu 16.04
语言:Python2.7
数据库:Redis,mongoDB
中间件:RabbitMQ
进程管理:Supervisor
如无必要,勿增实体。为什么要加这么多花里胡哨的东西来占用资源?咳咳,就是为了玩玩。
需求文档:
- 1.爬取某平台达人数据,包含主页数据和视频粉丝等详情数据;
- 2.每周更新一次数据;
- 3.可随时插入或更新某达人详情数据。
画个巨Low的架构图来看看:
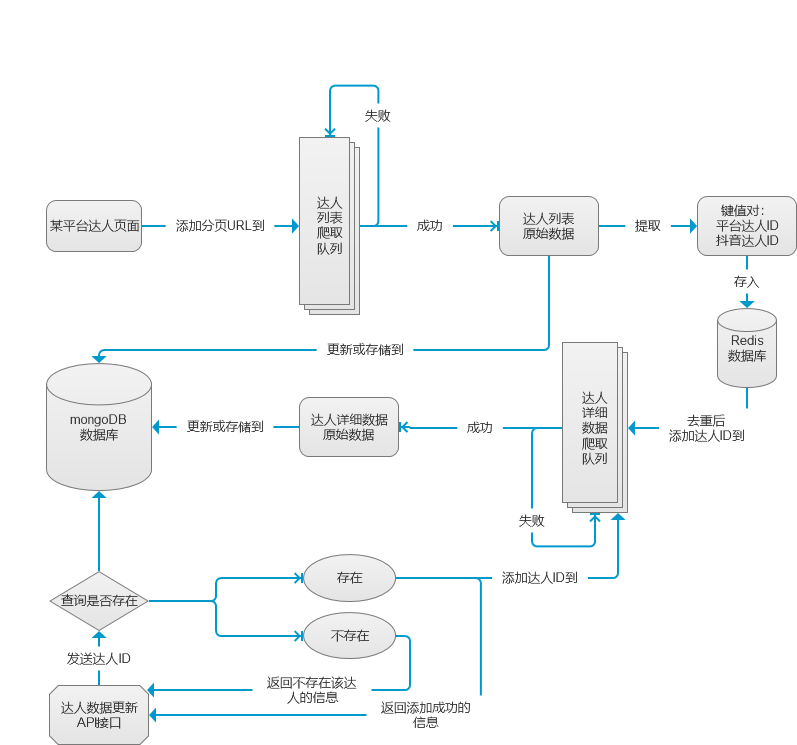
技术评估:
1.爬取频率:测测测!不要盲目自信设个延迟就溜了!需求一实际上是最基础的数据爬取和存储,还没涉及到数据处理层。但由于需要登录的cookie我只有一个,爬取频率要控制好(请求后延迟或消费者回调延迟都可以),线程嘛也不敢多开(python的multiprocessing模块中pool() + pool.map()开启多线程很方便,谨慎食用咯)。而多条MQ队列同时发布和消费本身就是多线程啊,How to DO?切记,如果没有十足的把握(让爬虫足够稳定),别把不同的消费者写在同一个脚本里。除非……把爬虫脚本写成API,通过发送请求来回调不同的队列消息,效果也不错,这样甚至能够通过设置请求频率来控制爬取频率。
2.数据去重:每周更新一次数据意味着每周都要爬一次该平台的所有达人,一般每周新增的达人不多,所以要在爬取时做去重处理。首先说一下为什么选择了mongoDB而不是MySQL?由于该平台爬取到的是json数据(包含list),故用mongoDB存储再好不过(懒人必备,这样就不用考虑存哪些字段,全拿下就行了,后期再按需求处理)。而对于json数据的处理,尽可能和爬取分开,在爬取过程中批量处理结构化数据,会非常影响爬虫效率,又或者,将爬取和数据处理分开在不同线程处理(切勿让数据处理延长单个线程的时间),可服务器资源有限的前提下这并不是一个高效的方法。既然不用MySQL,那去重我选择Redis。用极限思维来考虑,当爬虫级别上千万以后(这里还没考虑高并发读写),每一次查询都会消耗不少时间,爬虫效率也会逐渐降低,所以要在读写上尽可能提高效率。把键值对存到Redis的哈希表(上锁)来实现去重,效果可以媲美MySQL。
3.稳定性:有这么多花里胡哨的东西,稳定性要考虑的可多咯。首先是爬虫的稳定性,要控制频率,关于重试和超时,不要设置多次重试,就这一个cookie,失败了赶紧把URL重新塞回队列,等下一次爬取就行(非常有必要延迟一段时间后再启动下一次)。如果更加谨慎,可以新增一条与原队列延迟不同的「回笼」队列,来专门处理异常请求。RabbitMQ的话要考虑宕机的问题(谁知道什么时候挂机),这是要做好队列持久化;不小心断开连接也要做好信息不丢失的处理,没处理完的消息,保持下次连上的时候发布者能够重新发送;还有非常非常重要的——自动连接,如果想省心地挂上爬虫就和朋友去嗨皮,最好让RabbitMQ不检测心跳,这样就不会造成服务端主动断开连接(特别是延迟较大的时候)。以上几点也是我不采用Python自带的Queue模块的原因,显然使用中间件对队列的可控性更高,可灵活应对更多特殊情况。
4.灵活性:这是针对可随时插入或更新某条数据而言的。比方说,距离上次数据更新已经过去一星期了,公司运营小姐姐想要最新的某个达人的报价,怎么办?就这个问题我可以新增一条队列,叫「应急」队列什么的都行。这时她可以把这个达人的ID扔到「应急」队列中优先爬取(RabbitMQ的界面化操作非常友好),但这会有一个问题,万一不小心输错ID了怎么办?RabbitMQ可是照样发送的呀。不行不行,为了让运营部门省心,我可以开放一个API接口,当ID插入队列之前,我会判断该达人ID是否存在于达人库中,如果不存在该达人则不插入该消息。同理,公司不同岗位的同事的数据需求都可能不同,可按需开放接口。涉及到共用一个数据库,还要考虑如何去避免数据混淆(可构造列表存放不同时间维度的数据,同时也是为了处理时数据对齐)。
5.资源分配:如果可以的话,RabbitMQ一台,Redis一台,爬虫一台,数据库一台,代理的话,免费的可以用西刺(很不稳定)……当然,我只是玩玩,我全部用一台,嘻嘻。
程序设计
来了,要开始了,兄弟
创建虚拟环境
用python做项目要养成各项目间环境独立的习惯(当然如果使用的是docker那就方便多了) 现在我创建一个名为/spiders的文件夹并在该文件下创建名为env_py2.7虚拟环境:
root@ubuntu:~# cd /spiders
root@ubuntu:/spiders# virtualenv env_py2.7
激活环境与退出环境:
root@ubuntu:/spiders# source env_py2.7/bin/activate
(env_py2.7) root@ubuntu:/spiders# deactivate
创建项目并安装所有依赖
在/spiders文件夹下创建/xingtu文件夹,代码和配置等就放在这下面了。
root@ubuntu:/spiders/xingtu# tree
.
├── agent_proxy.py # 此文件存放user-agents和代理
├── cookie.txt # 此文件存放cookie
├── get_kol_detail.py # 爬取达人详细数据的脚本
├── get_kol_list.py # 爬取达人列表
├── requirements.txt # 打包依赖
├── send_id_api.py # 更新达人数据的接口
├── send_pages.py # 发布url消息
└── xingtu_supervisord.conf # 进程管理配置
0 directories, 8 files
这个小爬虫要用到的库及作用如下,我把所有依赖写进requirements.txt:
pika # 连接操作rabbitmq
requests # 爬虫
redis # 连接redis
pymongo # 连接mongoDB
flask # 编写API
flask_cors
pandas # 数据处理
gevent # 并发处理
在虚拟环境中直接安装所有依赖:
(env_py2.7) root@ubuntu:~# pip install -r /spiders/xingtu/requirements.txt
连接RabbitMQ
记得把heartbeat设为0,省去手动重连的后顾之忧:
credentials = pika.PlainCredentials(账号, 密码)
connection = pika.BlockingConnection(pika.ConnectionParameters(host='服务器IP',
credentials=credentials,
heartbeat=0 )) # 设置heartbeat为0,意味着不检测心跳,server端不会主动断开连接
channel = connection.channel()
创建发布队列,发送URL(send_pages.py)
创建一个名为'xingtu_page'的队列来开始发布我们的爬取链接吧:
def get_page(page):
# url = '爬取 {} 的URL'.format(page) # 更新url的page参数
channel.queue_declare(queue='xingtu_page', durable=True)
channel.basic_publish(exchange='',
routing_key='xingtu_page',
body=url,
properties=pika.BasicProperties(
delivery_mode=2, # 消息持久化
))
if __name__ == '__main__':
pool = Pool(1) #只开一个线程
pool.map(get_page, range(1,2000)) #多线程工作
pool.close()
pool.join()
connection.close()
爬取达人列表(get_kol_list.py)
关于爬取中的超时和重试,可以自己定义,这里直接用requests封装好的:
req = requests.Session()
req.mount('http://', HTTPAdapter(max_retries=1))
req.mount('https://', HTTPAdapter(max_retries=1))
消费者回调函数:
def callback(ch, method, properties, body):
try:
'''调用get_kol函数爬取'''
get_kol_id(body)
time.sleep(20)
ch.basic_ack(delivery_tag=method.delivery_tag) # 消费者每次收到消息,要通知一声:已经收到,如果消费者连接断了,rabbitmq会重新把消息放到队列里,下次消费者可以连接的时候,就能重新收到丢失消息
except:
'''请求失败则把url重新放回队列'''
channel.basic_publish(exchange='',
routing_key='xingtu_page',
body=body,
properties=pika.BasicProperties(
delivery_mode=2, # 消息持久化
))
time.sleep(120) # 爬取失败就等两分钟再继续
爬取并且发布消息到新队列::
def get_kol_id(url):
headers = {'User-Agent': agent_proxy.get_agent()}
cookies = open(u'/spiders/xingtu/cookie.txt','r').read() # cookie写在cookie.txt里面
cookies_dict = {}
'''对原始cookies构造字典格式'''
for line in cookies.split(';'):
key, value = line.split('=', 1) # 1代表只分一次,得到两个数据
key = key.replace(' ', '')
cookies_dict[key] = value
list_kol = req.get(url, headers=headers, cookies=cookies_dict, timeout=20, verify=False).json() # 这里使用req是因为上面对resquests设置了重试机制
for author in list_kol['data']['authors']:
id_xingtu = author['id']
id_douyin = author['core_user_id']
if my_redis.hget('hash_kolid', id_douyin) == None: # redis 通过查询hash表去重
my_redis.hsetnx('hash_kolid', id_douyin, id_xingtu) # 将id写入redis,key为抖音id,value为达人在该平台id
channel.queue_declare(queue='xingtu_kol_id', durable=True) # 创建队列,发布达人的该平台id
channel.basic_publish(exchange='',
routing_key='xingtu_kol_id',
body=id_xingtu,
properties=pika.BasicProperties(
delivery_mode=2, # 消息持久化
))
else:
pass
if list(db_kl.find({'core_user_id': id_douyin})) == []: # 插入mongodb时去重.防止redis数据丢失,mongodb依然能够正常去重保存
db_kl.insert(author)
else:
pass
开始消费:
if __name__ == '__main__':
channel.basic_consume('xingtu_page',
callback,
auto_ack=False)
channel.start_consuming()
爬取达人详细数据(get_kol_detail.py)
消费者回调函数
def callback(ch, method, properties, body):
try:
'''调用get_kol_detail函数爬取'''
get_kol_detail(body)
time.sleep(30)
ch.basic_ack(delivery_tag=method.delivery_tag) # 消费者每次收到消息,要通知一声:已经收到,如果消费者连接断了,rabbitmq会重新把消息放到队列里,下次消费者可以连接的时候,就能重新收到丢失消息
except:
'''请求失败则把id重新放回队列'''
channel.basic_publish(exchange='',
routing_key='xingtu_kol_id',
body=body,
properties=pika.BasicProperties(
delivery_mode=2, # 消息持久化
))
time.sleep(120)
根据达人在该平台ID爬取达人详细数据:
def get_kol_detail(id_xingtu):
print id_xingtu
headers = {'User-Agent': agent_proxy.get_agent()}
cookies = open(u'/spiders/xingtu/cookie.txt','r').read() # cookie写在cookie.txt里面
cookies_dict = {}
'''对原始cookies构造字典格式'''
for line in cookies.split(';'):
key, value = line.split('=', 1) # 1代表只分一次,得到两个数据
key = key.replace(' ', '')
cookies_dict[key] = value
'''列出所有待爬取url'''
url_kol_index = '爬取的{}URL1'.format(id_xingtu) # 达人主页信息
url_kol_order = '爬取的{}URL2'.format(id_xingtu) # 达人任务信息
url_kol_item = '爬取的{}URL3'.format(id_xingtu) # 达人个人作品数据,作品总数据,代表作品数据
url_kol_video = '爬取的{}URL4'.format(id_xingtu) # 达人近15条视频数据
url_kol_daily_fans = '爬取的{}URL5'.format(id_xingtu) # 达人粉丝趋势变化
url_kol_fans_detail = '爬取的{}URL6'.format(id_xingtu) # 达人粉丝详情
url_dict = [{'kol_index': url_kol_index},
{'kol_order': url_kol_order},
{'kol_item': url_kol_item},
{'kol_video': url_kol_video},
{'kol_daily_fans': url_kol_daily_fans},
{'kol_fans_detail': url_kol_fans_detail}]
for url in url_dict:
time.sleep(5)
kol_detail = req.get( url.values()[0], headers=headers, cookies=cookies_dict, timeout=20, verify=False ).json()
if kol_detail['msg'] == u'成功':
db_kd.update( {'id': id_xingtu }, {'$set': { url.keys()[0] : kol_detail }}, upsert=True ) # upsert=True,则存在时修改,不存在时插入
else:
db_kd.update({'id': kol_detail['data']['nothing']}, {'$set': {url.keys()[0]: kol_detail}}, upsert=True) # 这行一定会报错,从而执行回调函数中的异常处理,因为kol_detail['data']['nothing']根本不存在
实时更新达人详细数据(send_id_api.py)
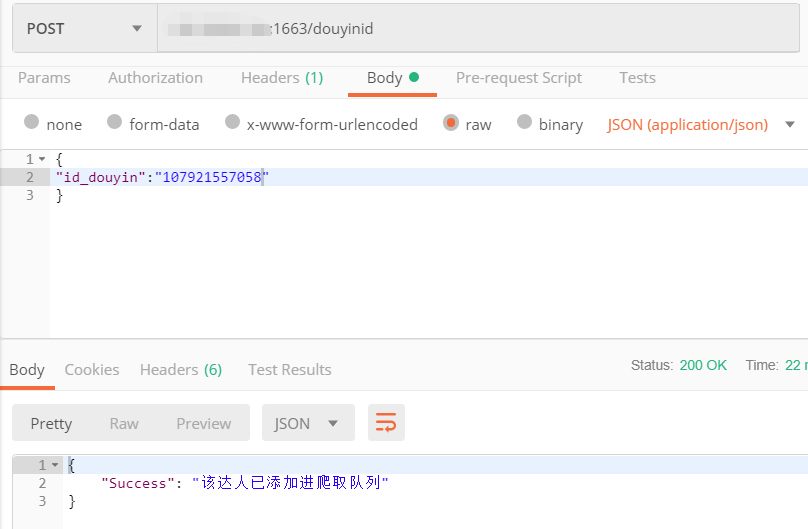
请求的json数据是该达人在抖音平台的ID(这里并未对请求的数据进行加密,如果是企业级开发的话对API的安全性和并发性能应做更加谨慎的设计),如果达人在该平台则提示「已添加」,否则提示「未收录」。
server = flask.Flask(__name__)
CORS(server, resources=r'/*')
@server.route('/douyinid', methods=['get', 'post'])
def registerPost():
# post请求获取请求的参数,返回结果类型是json
content = request.get_json()
if list(db_kl.find({'core_user_id': int(content['id_douyin'].encode('utf-8'))})) == []: # content['id_douyin']为unicode编码,需要转成utf-8再int
reply = jsonify({'Error': '该平台暂未收录该达人数据'})
else:
data_kol = pd.DataFrame(list(db_kl.find({'core_user_id': int(content['id_douyin'].encode('utf-8'))})))
channel.basic_publish(exchange='',
routing_key='xingtu_kol_id',
body=data_kol.loc[0]['id'], # 消息为该平台id
properties=pika.BasicProperties(
delivery_mode=2, # 消息持久化
))
reply = jsonify({'Success': '该达人已添加进爬取队列'})
reply.headers['Access-Control-Allow-Origin'] = '*'
reply.headers['Access-Control-Allow-Methods'] = 'POST'
reply.headers['Access-Control-Allow-Headers'] = 'x-requested-with,content-type'
return reply
启动flask API服务:
if __name__ == '__main__':
WSGIServer(('0.0.0.0', 端口), server).serve_forever()
启动项目
所有脚本的启动我就交给supervisor这个进程管理工具啦,配置也是相当地简单,每一个脚本的运行单独作为一个进程(当然可以通过定义类来把所有脚本写成一个框架,但进程相互独立也有好处,至少在没留log文件的时候调试起来要方便的多),在/spiders/xingtu/xingtu_supervisord.conf中写入以下配置:
[program:send_pages]
command=/spiders/env_py2.7/bin/python /spiders/xingtu/send_pages.py
#priority是权重,数字越大,优先级越高
priority=999
autostart=true
autorestart=unexpected
#startsecs表示进程启动多长时间后视为正常运行
startsecs=0
startretries=3
redirect_stderr=true
stdout_logfile=/tmp/stdout.log
stdout_logfile_maxbytes=10MB
stdout_logfile_backups=10
[program:get_kol_list]
command=/spiders/env_py2.7/bin/python /spiders/xingtu/get_kol_list.py
priority=998
autostart=true
autorestart=unexpected
startsecs=0
startretries=3
redirect_stderr=true
stdout_logfile=/tmp/stdout.log
stdout_logfile_maxbytes=10MB
stdout_logfile_backups=10
[program:get_kol_detail]
command=/spiders/env_py2.7/bin/python /spiders/xingtu/get_kol_detail.py
priority=997
autostart=true
autorestart=unexpected
startsecs=0
startretries=3
redirect_stderr=true
stdout_logfile=/tmp/stdout.log
stdout_logfile_maxbytes=10MB
stdout_logfile_backups=10
[program:send_id_api]
command=/spiders/env_py2.7/bin/python /spiders/xingtu/send_id_api.py
priority=996
autostart=true
autorestart=unexpected
startsecs=0
startretries=3
redirect_stderr=true
stdout_logfile=/tmp/stdout.log
stdout_logfile_maxbytes=10MB
stdout_logfile_backups=10
我的supervisor是在全局环境中的python2.7中安装的,激活环境:
root@ubuntu:~# source activate python2.7
通过supervisor运行所有脚本:
(python2.7) root@ubuntu:~# supervisord -c /spiders/xingtu/xingtu_supervisord.conf
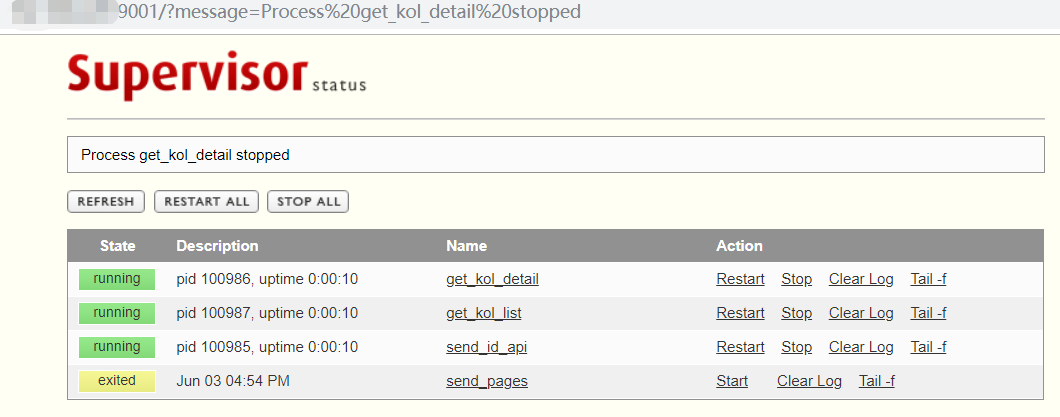
查看supervisor的运行状态:
(python2.7) root@ubuntu:~# supervisorctl -c /spiders/xingtu/xingtu_supervisord.conf status
get_kol_detail RUNNING pid 100986, uptime 0:00:03
get_kol_list RUNNING pid 100987, uptime 0:00:03
send_id_api RUNNING pid 100985, uptime 0:00:03
send_pages EXITED Jun 03 04:54 PM
我还可以通过浏览器访问supervisor的服务端,对所有进程进行重启,暂停等操作:
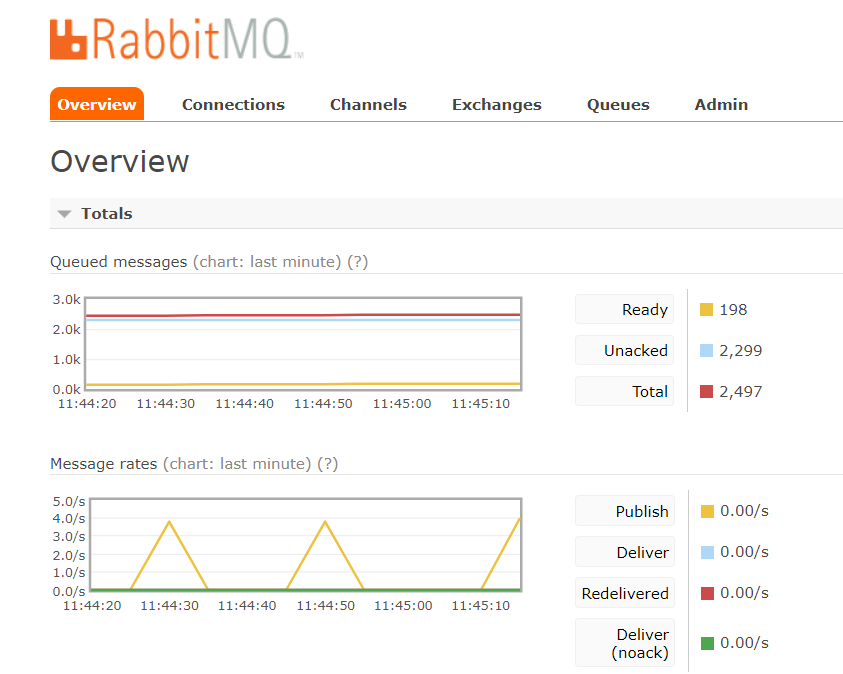
 看一下RabbitMQ的控制面板:
看一下RabbitMQ的控制面板:
 查看一下redis:
查看一下redis:
root@ubuntu:~# redis-cli -a 密码
127.0.0.1:6379> hgetall hash_kolid
1) "3891903335244664"
2) "6680368576479625224"
3) "59359411419"
4) "6638835397155618820"
......
找一个已经在数据库的达人ID,测试一下更新达人详细数据的API:
 这个入门级的小爬虫,大功告成啦!
这个入门级的小爬虫,大功告成啦!
写在后面
今天是高考的日子,前几天我无意中翻出了我去年毕业答辩的论文,想起了我的恩师们,同学们,我的大学舍友,历历在目。每一年毕业季会让人走向一座更高的山,跨向更广的海,但也让我们学会承受离别带来的伤感。
有时候我会后悔,为什么上学时候不好好学习,这个世界太多太多的魅力源自于science and technology,而自己只能羡慕别人的飞跃。但更多时候是欣喜,我的舍友既没有和我讨论薛定谔的猫也没有辩证忒休斯之船,但我记得,去年世界杯我们因为C罗的帽子戏法狂欢一宿,每年S系列赛的时候我们都会拿好小凳子围着给中国队加油,每次检查作业的前一晚都会手机闪光灯都会「派上用场」,每一次考试都会花光前面16周的记忆和运气......当流年成为历史,当老去成为定势,自己就会小心翼翼擦拭掉这些尘封回忆的灰,静默怀念。
OK,其实这部分后记本是前记,没有牢骚,就不会有这篇文章。我想说什么呢?正好可以用我毕业论文的一句话来表达:
大学的路虽走到了终点,而求知求学的征途长路漫漫。
记于2019/6/7,初夏